카프카(Kafka)는 생각보다 쉬운 툴이다. 하지만 장기적으로 운영할 시스템 환경은 간단히 한번 돌리고 마는 경우와 고려해야 할 것들이 제법된다. 운영 관점의 설정 값들을 엉뚱하게 해놓으면 잘 차려진 밥상에 꼭 재를 뿌리게 된다. 이런 잘못을 범하지 않으려면 Kafka라는 이름뿐만 아니라 이 도구가 어떤 방식으로 동작하는지 깊게 들어가볼 필요가 있다. 물론 그 동작 방식을 운영 환경과 어울려 살펴봐야만 한다.
상태 조회하기
운영을 할려면 가장 먼저 필요한 일이 시스템의 상태를 살펴볼 수 있는 도구가 필요하다.

alias monitor='kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper localhost:2181' alias topic='kafka-topics.sh --zookeeper localhost:2181' alias consumer='kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic'
이미 있는 명령들을 “쉽게 쓰자”라는 차원에서 alias를 정의하긴 했다. consumer의 경우에는 Producer를 통해 생성된 Topic 데이터가 정상적으로 생성됐는지를 확인하기 위해 필요하다. 나머지 2 개의 명령은 어떤 경우에 사용하는게 좋을까?
topic 명령은 일반적인 토픽 관리를 위한 기능들을 모두 제공한다. 만들고, 변경하고, 삭제하는 모든 기능을 이 스크립트 명령으로 제어한다. 주목하는 토픽 상태는 describe 옵션으로 확인할 수 있다. 체크해야할 사항은 2가지다.
- 현재 토픽의 Partition의 수와 Replica가 어떤 노드에 배정이 되어 있는지를 확인할 수 있다.
- 개별 Partition의 현재 Leader가 어떤 놈인지를 확인할 수 있다.
이 두가지 정보는 이후에 Kafka cluster의 성능 튜닝을 위해 파악해야할 정보다.
monitor 명령은 토픽의 데이터를 subscribe한 특정 그룹으로의 데이터 전달이 제대로 이뤄지고 있는지를 각 Partition별로 확인할 수 있도록 해준다.
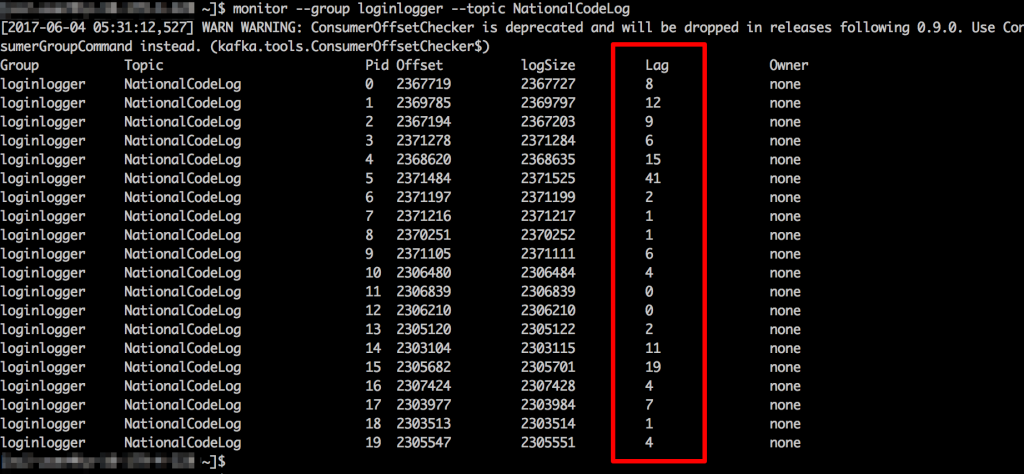
출력 결과의 Lag 항목을 보면 현재 처리를 위해 각 파티션에서 대기하고 있는 데이터 개수를 확인할 수 있다. 특정 그룹에서 소비해야할 토픽 데이터의 건수가 증가하지 않고 일정 수준을 유지한다면 Kafka 시스템이 클러스터로써 제대로 동작을 하고 있다는 것을 의미한다. 기본 명령의 출력 결과가 파티션별이기 때문에 총합을 볼려면 각 파티션들의 합을 구하는 기능을 만들어야 아래와 같은 스크립트로 만들 수 있다.
#!/bin/sh
kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper localhost:2181 --group $1 --topic $2 | egrep -v "Group" | awk -v date="$(date +"%Y-%m-%d %H:%M:%S ")" '{sum+=$6} END {print date sum}'
만일 특정 그룹과 토픽에 대한 상시적인 모니터링이 필요하다면 위 스크립트를 한번 더 감싸는 아래의 monitor.sh 스크립트를 작성해서 돌리면 된다. 이 스크립트는 문제가 될 그룹과 토픽에 대한 정보를 30초 단위로 조회하여 출력한다.
#!/bin/sh while (true) do /home/ec2-user/total.sh groupname topic 2> /dev/null; sleep 30; done;
당연한 시간을 너무 짧게 분석하는 것도 되려 시스템 자체에 부하를 줄 수 있다는 사실을 잊지는 말자!
Kafka 최적화하기
Kafka를 단순히 로그 수집용이 아닌 여러 토픽들을 섞어서 메시징 용도로 사용하는 경우에 최적화는 큰 의미를 갖는다. 특히 여러 토픽을 다루는 환경에서 Kafka 운영자는 다음 사항들을 꼼꼼하게 챙겨야 한다.
- 토픽의 종류별로 데이터의 양이 틀려질 수 있다.
- 연동하는 서비스 시스템의 성능이 클러스터의 성능에 영향을 미칠 수 있다.
따라서 효율적이고 안정적인 메시징 처리를 위해서 토픽이 데이터 요구량에 대응하여 적절한 파티션들로 구성되어 있는지를 확인해야 한다. 한 토픽에 여러 파티션들이 있으면, 각각의 파티션이 독립적으로 데이터를 처리해서 이를 Consumer(or ConsumerGroup)으로 전달한다. 즉 데이터가 병렬 처리된다. 병렬 처리가 되는건 물론 좋다. 하지만 이 병렬 처리가 특정 장비에서만 처리되면 한 장비만 열라 일하고, 나머지 장비는 놀게 된다.
일을 하더라도 여러 장비들이 빠짐없이 일할 수 있는 평등 사회를 실현해야한다. Kafka 사회에서 평등을 실현할려면 토픽을 클러스터내의 여러 장비에서 고르게 나눠 실행해야한다. 이런 나눔을 시스템 차원에서 알아서 실현해주면 운영하는 사람이 신경쓸 바가 없겠지만, 현재 버전(내가 사용하는 버전)은 해줘야한다. -_-;;;
평등 실행을 위해서는 일단 일하길 원하는 노드에 데이터가 들어가야 한다. 따라서 Replica 조정을 먼저 해준다. 조정 완료 후 이제 리더를 다시 뽑는다. 리더를 뽑는 방법은 아래 move.json 파일에서 보는 바와 같이 replicas 항목들의 클러스터 노드의 sequence 조합을 균일하게 섞어야 한다. 예처럼 2, 1, 3, 2, 1 과 같이 목록의 처음에 오는 노드 아이디 값이 잘 섞이도록 한다.
{"partitions": [
{"topic": "Topic", "partition": 0, "replicas": [2,1,3]},
{"topic": "Topic", "partition": 1, "replicas": [1,2,3]},
{"topic": "Topic", "partition": 2, "replicas": [3,1,2]},
{"topic": "Topic", "partition": 3, "replicas": [2,1,3]},
{"topic": "Topic", "partition": 4, "replicas": [1,2,3]},
{"topic": "Topic", "partition": 5, "replicas": [2,1,3]},
{"topic": "Topic", "partition": 6, "replicas": [3,1,2]},
{"topic": "Topic", "partition": 7, "replicas": [1,2,3]},
{"topic": "Topic", "partition": 8, "replicas": [2,1,3]},
{"topic": "Topic", "partition": 9, "replicas": [3,1,2]}
],
"version":1
}
그리고 아래 명령을 실행해서 섞인 Replica설정이 먹도록 만든다.
kafka-reassign-partitions.sh --reassignment-json-file manual_assignment.json --execute
물론 시간을 줄일려면 최초 단계에 Replicas 개수가 같은 replica 노드로 섞어주기만 하면 가장 좋다. 섞는 것만 한다면 작업 자체는 얼마 시간없이 바로 처리된다.
kafka-preferred-replica-election.sh --zookeeper localhost:2181 --path-to-json-file election.json
이제 리더를 각 클러스터의 여러 노드로 분산시키면 된다. 특정한 토픽만 지정해서 분할을 할려면 분할 대상을 아래 election.json 파일과 같은 형태로 작성해서 이를 위 명령의 파라미터로 넘긴다. 특정한게 아니라 전체 시스템의 모든 토픽, 파티션 수준에서 재조정을 할려면 별도 파일없이 실행시키면 된다.
{
"partitions":
[
{"topic": "Topic", "partition": 0},
{"topic": "Topic", "partition": 1},
{"topic": "Topic", "partition": 2},
{"topic": "Topic", "partition": 3},
{"topic": "Topic", "partition": 4},
{"topic": "Topic", "partition": 5},
{"topic": "Topic", "partition": 6},
{"topic": "Topic", "partition": 7},
{"topic": "Topic", "partition": 8},
{"topic": "Topic", "partition": 9}
]
}
이렇게 설정을 변경하면 Kafka 시스템이 라이브 환경에서 변경을 시작한다. 하지만 변경은 쉽지 않다는거… 좀 시간이 걸린다. 작업이 완료되지 않더라도 위의 설정이 제대로 반영됐는지 topic의 describe 명령으로 확인할 수 있다.
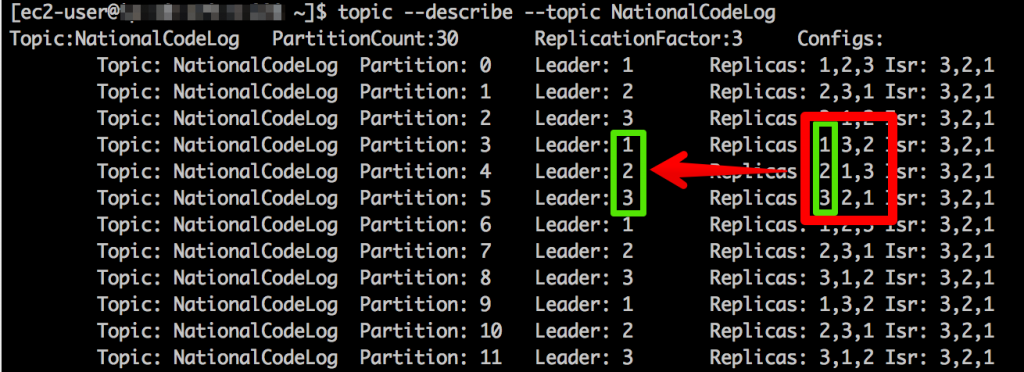
Replicas 항목들이 분산 노드들에 공평하게 배포되었고, 등장 순서에 따라 Leader가 적절하게 분산됐음을 확인한다. 만약 Replicas의 가장 앞선 노드 번호가 리더가 아닌 경우라면 아직 리더 역할을 할 노드가 제대로 실행되지 않았다는 것이다. 막 실행한 참이라면 logs/state-change.log 파일을 tail로 걸어두면 리더 변경이 발생했을 때를 확인할 수 있다. 어제까지 멀쩡했는데 오늘 갑자기 그런다면?? OMG 장비를 확인해보는게 좋을 듯 싶다. 🙂
변경이 마무리되는데까지는 좀 시간이 걸린다. 라이브 환경에는 특히 더할 수 있다. OLTP 작업들이 많다면 이런 튜닝 작업은 눈치 안보고 할 수 있는 시간에 스리슬적 해치우는게 좋다. 아니면 새벽의 한가한 때도??? -_-;;
Conclusion
이 과정을 거쳐서 정리를 마무리하면 대강 아래와 같은 최적화 과정이 절절한 그래프를 얻을 수 있다.
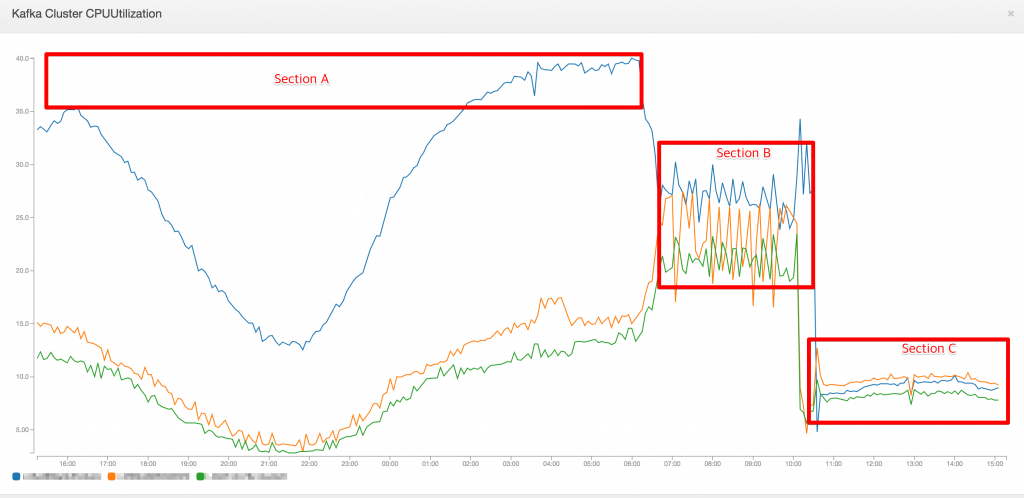
- Section A – Leader 설정이 클러스터의 특정 노드에 집중된 상태
- Section B – __consumer_offests 토픽의 replication 변경 및 leader 설정 변경
- Section C – 설정 변경 적용 완료.
Kafka 어드민 도구
어드민 활동을 좀 더 쉽게 할 수 있는 도구로 LinkedIn 개발팀에서 공유한 도구들이 아래에 있다. 이 도구의 특징은 간단한 설치 방법과 함께 전반적인 설정들을 손쉽게 변경할 수 있는 방안을 제공해준다.
- https://github.com/linkedin/kafka-tools
- https://github.com/linkedin/kafka-tools/wiki
예를 들어 Topic의 데이터를 Auto commit 방식이 아닌 manual commit 방식을 사용하는 경우, __consumer_offsets 이라는 topic이 자동 생성된다. 못보던 놈이라고 놀라지 말자. 기본값이라면 아마도 이 토픽의 replication이 단일 노드(replication factor = 1)로만 설정되어 있다. 메시지 큐를 Kafka로 구현한 내 경우에 모든 토픽을 manual commit 방식으로 처리한다. 그런데 이 설정이면 __consumer_offsets 토픽의 리더 노드가 맛이 가면 커밋을 못하는 지경이 되버린다. 결국 전체 데이터 처리가 멈춰버린다.
이런 경우를 사전에 방지하기 위해 __consumer_offsets 토픽의 replicas 설정이 올바른지 꼭 확인해야 한다. 그리고 설정이 잘못됐다면 replication 설정을 반드시 수정해주자. 자책하지 말자. Kafka의 기본 설정은 노트북에서도 돌려볼 수 있도록 안배가 되어 있다. 한번쯤 고생해봐야 쓰는 맛을 알거라는 개발자의 폭넓은 아량일 것이다.
이 어드민 도구는 아래 Replication creation script에서 보는 바와 같이 별도의 json 파일없이도 이를 실행할 수 있다.
kafka-assigner -z localhost:2181 -e set-replication-factor --topic __consumer_offsets --replication-factor 3
이 기능 이외에도 대부분이 토픽들을 한방에 정리할 수 있는 여러 기능들을 제공한다. 깃헙 Wiki 페이지에서 각 명령을 실행하는 방법을 확인할 수 있다.
Kafka administration summary
몇 가지 방법들을 썰로 좀 풀어봤지만, 기본적인 사항들을 정리해보면 아래와 같다.
Basic configuration
- Cluster size = 3 – Cluster는 최소 3개 이상이어야 하며, 운영 노드의 개수는 홀수가 되도록 한다.
- Partition size = 8 – 기본 Partition은 개별 노드의 CPU Core 개수 혹은 그 이상을 잡는다.
- Replication factor = cluster size – Replication factor는 처리하는 데이터가 극적으로 작지 않는다면 Cluster 개수와 동일한 값이 되도록 한다.
- JVM Option – 마지막까지 괴롭히는 놈이다. 현재 테스트중인 옵션
export KAFKA_HEAP_OPTS="-Xmx9g -Xms9g" export KAFKA_JVM_PERFORMANCE_OPTS="-XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80"
Tuning
- Partition의 개수를 늘린다. 토픽의 alter 명령을 사용해서 partition의 크기를 변경한다.
- 토픽의 replication factor 확인하고, 각 partition의 리더가 전 클러스터에 균일하게 배분되었는지 확인한다.
- 수동 commit 모드를 사용중이라면 __consumer_offsets 토픽의 partition, replication, leader 설정이 올바른지 확인한다.
- 위에서 설명한 total.sh 등 명령으로 특정 topic 및 group의 consuming이 누적되지 않고 즉각적으로 처리되는지 확인한다.
- Kafka의 garbage collection이 정상적으로 실행되고 있는지 확인한다. 데이터 적체가 발생되면 처리되던 데이터도 처리안된다.
- 주기적으로 토픽의 leader 및 replication 설정이 적절한지 점검해준다.
대강의 경험을 종합해봤다.
앞으로는 잘 돌아야 하는데 말이다.

Reading for considerations
- Java G1 GC – http://www.oracle.com/technetwork/articles/java/g1gc-1984535.html
- Kafka optimization and configuration – http://docs.confluent.io/current/kafka/deployment.html
앞으로 설정할 때 이 부분을 좀 더 파봐야할 것 같다.